
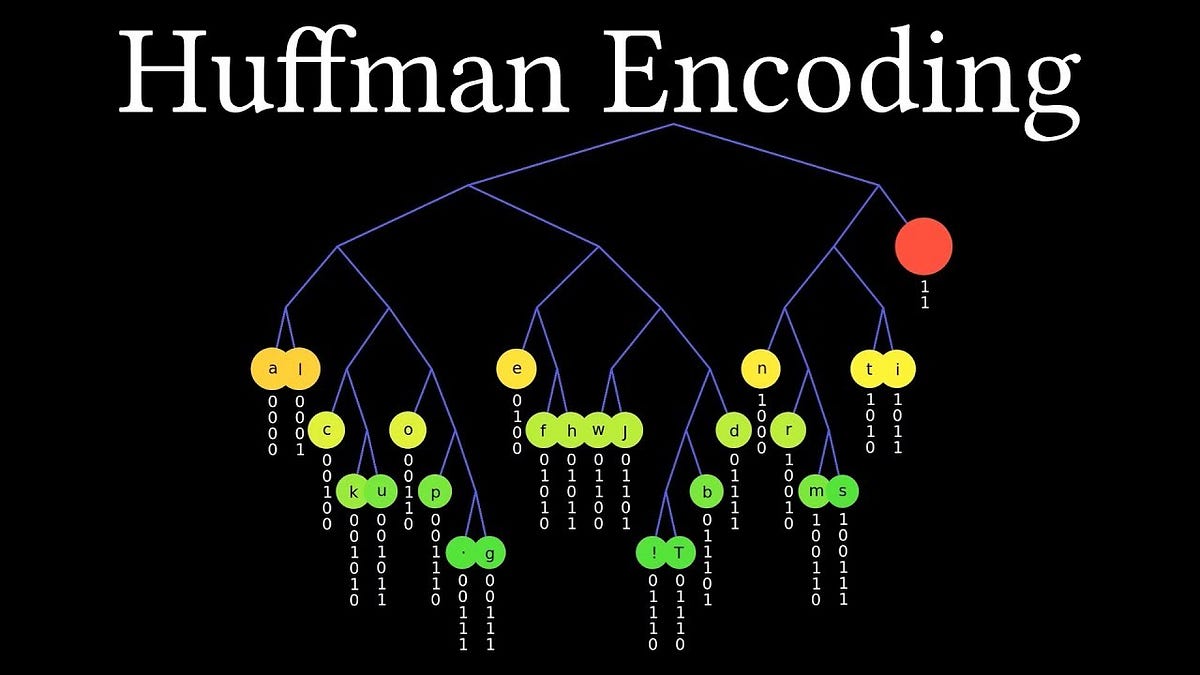
Imagine packing your suitcase for a trip. At first, you arrange everything neatly, but as you add more items, you realise that some need to be reshuffled to make room for new essentials. Adaptive Huffman Coding works much like that—constantly rearranging and optimising its structure as new data arrives, ensuring the most efficient use of space without losing any information.
This dynamic compression technique exemplifies how adaptability leads to efficiency—a principle as relevant to data processing as it is to any modern discipline rooted in constant change.
The Essence of Adaptivity in Data Compression
Traditional Huffman Coding assigns fixed codes based on the frequency of symbols in a dataset. But what happens when data arrives in a stream, continuously changing in nature? A fixed code table quickly becomes outdated, leading to inefficiencies.
Adaptive Huffman Coding solves this problem by updating the coding tree on the fly. Each time a symbol appears, the algorithm adjusts its structure, ensuring that frequently occurring symbols receive shorter codes while rare ones get longer ones. This continual evolution enables high compression ratios even when the data distribution shifts.
Learners pursuing a data science course often encounter Huffman algorithms early in their studies, as these form the backbone of efficient data storage and transmission systems. Understanding such techniques lays the groundwork for mastering real-world applications in analytics and machine learning.
Dynamic Tree Building: Learning as Data Flows
In many ways, Adaptive Huffman Coding behaves like a student learning in real time. As new information appears, it adapts its understanding and reorganises priorities. The algorithm maintains a binary tree structure that represents symbol frequencies.
Each node’s position in the tree is recalibrated based on the latest data. This continuous rebalancing allows it to mirror live data behaviour without starting over, making it ideal for streaming applications like online communications or sensor data.
The approach not only saves space but also reduces redundancy, ensuring that each bit of data contributes meaningfully to the overall message.
Why Adaptivity Matters in Modern Systems
In a digital world dominated by streaming services, IoT sensors, and real-time analytics, static systems can’t keep up. Adaptivity is the new efficiency. Adaptive Huffman Coding exemplifies this shift—it thrives where flexibility and precision intersect.
Take video streaming platforms as an example. Each frame differs slightly from the previous one, and adaptive algorithms ensure that storage and bandwidth are optimised without sacrificing quality. This same principle applies to analytics pipelines, where data patterns evolve continuously.
Professionals enrolled in a data science course in Mumbai often explore how adaptive algorithms like this one can be integrated into real-time systems—where learning never stops and optimisation happens instantly.
Balancing Complexity and Speed
Every gain in adaptability comes with trade-offs. Adaptive Huffman Coding introduces computational overhead because it must update the tree structure continuously. However, for many applications, this extra effort pays off through improved compression and reduced storage costs.
It’s similar to a factory assembly line that recalibrates itself while running—slightly more complex to manage but far more efficient over time. Engineers and data scientists often evaluate these trade-offs depending on their system constraints.
The algorithm shines especially in scenarios where data patterns are unpredictable, offering a smart compromise between performance and precision.
From Storage Efficiency to Smarter Data Systems
At its core, Adaptive Huffman Coding embodies the philosophy of continuous improvement. It doesn’t wait for perfect conditions—it evolves as it goes, mirroring how modern data systems function.
This philosophy also resonates across broader areas of data management, analytics, and even artificial intelligence. Systems that can adapt in real time to shifting data patterns will define the next generation of innovation.
Those advancing through a data science course in Mumbai often discover that such adaptive principles underpin everything—from neural networks adjusting weights during training to recommendation systems refining suggestions with each new interaction.
Conclusion
Adaptive Huffman Coding represents a fundamental truth of data science—the best systems learn as they work. By continually updating its code tree, it reflects how intelligence, both human and artificial, thrives through adaptability.
Whether compressing a file or designing predictive models, the lesson remains the same: staying static limits potential, while adaptation drives progress.
For learners navigating a data science course, this concept serves as both a technical foundation and a broader metaphor for professional growth—adapt, optimise, and evolve as the data does.
Business Name: ExcelR- Data Science, Data Analytics, Business Analyst Course Training Mumbai
Address: Unit no. 302, 03rd Floor, Ashok Premises, Old Nagardas Rd, Nicolas Wadi Rd, Mogra Village, Gundavali Gaothan, Andheri E, Mumbai, Maharashtra 400069, Phone: 09108238354, Email: enquiry@excelr.com.
